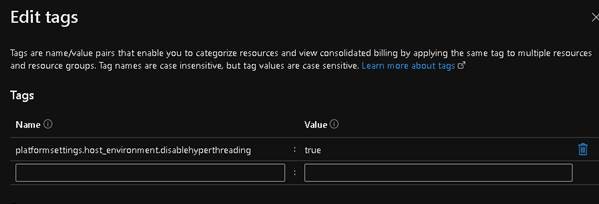
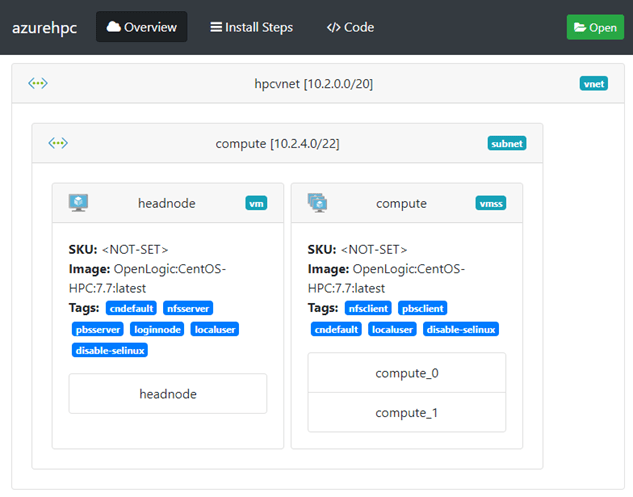
From the “Key Highlights from SNUG 2022“:
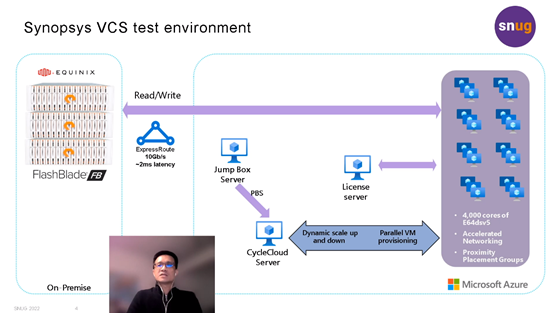
“One of the most attractive uses of the cloud for chip development is bursting VCS workloads. “Bursting” to the cloud is all about dynamic deployment of applications and allows customers to leverage the huge scale of compute that the cloud offers. While hosting design data completely on the cloud is simpler and more efficient, many customers want a hybrid scenario where they can store data on a wholly owned storage solution while leveraging Cloud as a Service (CaaS).
Microsoft Azure has worked with Pure Storage and Equinix to offer such a colocation hybrid solution for customers to gain the desired performance for EDA workloads. On Day 2 of SNUG 2022, Microsoft’s senior program manager, Raymond Meng-Ru Tsai, and Pure Storage’s technical director, Bikash Roy Choudhury, led a joint session to provide attendees with an in-depth perspective of running the industry’s highest performance simulation solution, Synopsys VCS® via Microsoft Azure and Pure Storage FlashBlade® at scale. They discussed best practices to verify parameters such as completion time, storage throughput patterns, and network route capabilities. This discussion also provided attendees with granular details of a tried-and-tested method to store data on a wholly owned FlashBlade device located in an Equinix data center while being connected to the Azure cloud for compute."
Synopsys users will be able to access SNUG content at SolvNetPlus.